Building an ML Workflow
In this section, we’ll create a ML workflow using Airflow operators, including Amazon SageMaker operators to build the recommender. You can download the companion Jupyter notebook to look at individual tasks used in the ML workflow. We’ll highlight the most important pieces here.
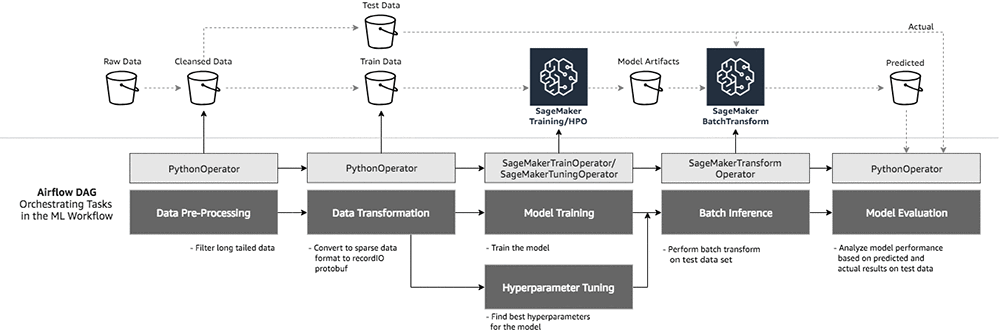
Data preprocessing
- As mentioned earlier, the dataset contains ratings from over 2 million Amazon customers on over 160,000 digital videos. More details on the dataset are here.
- After analyzing the dataset, we see that there are only about 5 percent of customers who have rated 5 or more videos, and only 25 percent of videos have been rated by 9+ customers. We’ll clean this long tail by filtering the records.
- After cleanup, we transform the data into sparse format by giving each customer and video their own sequential index indicating the row and column in our ratings matrix. We store this cleansed data in an S3 bucket for the next task to pick up and process.
The following
PythonOperatorsnippet in the Airflow DAG calls the preprocessing function:# preprocess the data preprocess_task = PythonOperator( task_id='preprocessing', dag=dag, provide_context=False, python_callable=preprocess.preprocess, op_kwargs=config["preprocess_data"])
NOTE: For this blog post, the data preprocessing task is performed in Python using the Pandas package. The task gets executed on the Airflow worker node. This task can be replaced with the code running on AWS Glue or Amazon EMR when working with large data sets.
Data Preparation
- We are using the Amazon SageMaker implementation of Factorization Machines (FM) for building the recommender system. The algorithm expects Float32 tensors in recordIO protobuf format. The cleansed data set is a Pandas DataFrame on disk.
- As part of data preparation, the Pandas DataFrame will be transformed to a sparse matrix with one-hot encoded feature vectors with customers and videos. Thus, each sample in the data set will be a wide Boolean vector with only two values set to 1 for the customer and the video.
- The following steps are performed in the data preparation task:
- Split the cleaned data set into train and test data sets.
- Build a sparse matrix with one-hot encoded feature vectors (customer + videos) and a label vector with star ratings.
- Convert both the sets to protobuf encoded files.
- Copy the prepared files to an Amazon S3 bucket for training the model.
The following
PythonOperatorsnippet in the Airflow DAG calls the data preparation function.# prepare the data for training prepare_task = PythonOperator( task_id='preparing', dag=dag, provide_context=False, python_callable=prepare.prepare, op_kwargs=config["prepare_data"] )
Model training and tuning
- We’ll train the Amazon SageMaker Factorization Machine algorithm by launching a training job using Airflow Amazon SageMaker Operators. There are couple of ways we can train the model.
Use SageMakerTrainingOperator to run a training job by setting the hyperparameters known to work for your data.
# train_config specifies SageMaker training configuration train_config = training_config( estimator=fm_estimator, inputs=config["train_model"]["inputs"]) # launch sagemaker training job and wait until it completes train_model_task = SageMakerTrainingOperator( task_id='model_training', dag=dag, config=train_config, aws_conn_id='airflow-sagemaker', wait_for_completion=True, check_interval=30 )Use SageMakerTuningOperator to run a hyperparameter tuning job to find the best model by running many jobs that test a range of hyperparameters on your dataset.
# create tuning config tuner_config = tuning_config( tuner=fm_tuner, inputs=config["tune_model"]["inputs"]) tune_model_task = SageMakerTuningOperator( task_id='model_tuning', dag=dag, config=tuner_config, aws_conn_id='airflow-sagemaker', wait_for_completion=True, check_interval=30 )Conditional tasks can be created in the Airflow DAG that can decide whether to run the training job directly or run a hyperparameter tuning job to find the best model. These tasks can be run in synchronous or asynchronous mode.
branching = BranchPythonOperator( task_id='branching', dag=dag, python_callable=lambda: "model_tuning" if hpo_enabled else "model_training")The progress of the training or tuning job can be monitored in the Airflow Task Instance logs.
Model inference
Using the Airflow SageMakerTransformOperator, create an Amazon SageMaker batch transform job to perform batch inference on the test dataset to evaluate performance of the model.
# create transform config
transform_config = transform_config_from_estimator(
estimator=fm_estimator,
task_id="model_tuning" if hpo_enabled else "model_training",
task_type="tuning" if hpo_enabled else "training",
**config["batch_transform"]["transform_config"]
)
# launch sagemaker batch transform job and wait until it completes
batch_transform_task = SageMakerTransformOperator(
task_id='predicting',
dag=dag,
config=transform_config,
aws_conn_id='airflow-sagemaker',
wait_for_completion=True,
check_interval=30,
trigger_rule=TriggerRule.ONE_SUCCESS
)
We can further extend the ML workflow by adding a task to validate model performance by comparing the actual and predicted customer ratings before deploying the model in production environment. In the next section, we’ll see how all these tasks are stitched together to form a ML workflow in an Airflow DAG.