High-Level Solution
We’ll start by exploring the data, transforming the data, and training a model on the data. We’ll fit the ML model using an Amazon SageMaker managed training cluster. We’ll then deploy to an endpoint to perform batch predictions on the test data set. All of these tasks will be plugged into a workflow that can be orchestrated and automated through Apache Airflow integration with Amazon SageMaker.
The following diagram shows the ML workflow we’ll implement for building the recommender system.
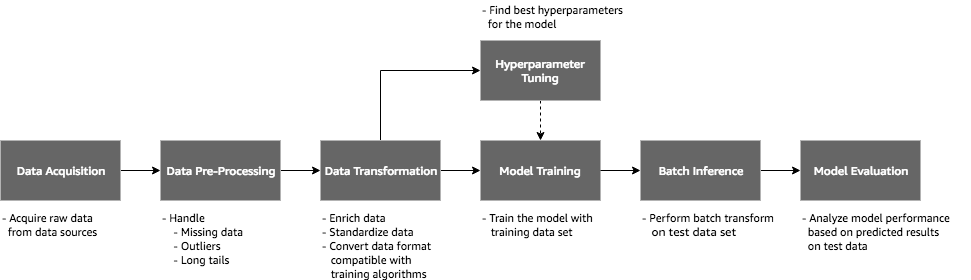
The workflow performs the following tasks:
- Data pre-processing: Extract and pre-process data from Amazon S3 to prepare the training data.
- Prepare training data: To build the recommender system, we’ll use the Amazon SageMaker built-in algorithm, Factorization machines. The algorithm expects training data only in recordIO-protobuf format with Float32 tensors. In this task, pre-processed data will be transformed to RecordIO Protobuf format.
- Training the model: Train the Amazon SageMaker built-in factorization machine model with the training data and generate model artifacts. The training job will be launched by the Airflow Amazon SageMaker operator.
- Tune the model hyperparameters: A conditional/optional task to tune the hyperparameters of the factorization machine to find the best model. The hyperparameter tuning job will be launched by the Amazon SageMaker Airflow operator.
- Batch inference: Using the trained model, get inferences on the test dataset stored in Amazon S3 using the Airflow Amazon SageMaker operator.